

فناوری رایانه ای - هوش مصنوعی
یادگیری ماشین تحت نظارت (Supervised Machine Learning) چیست؟
یادگیری نظارتشده نوعی یادگیری ماشینی است که در آن یک مدل از دادههای برچسبگذاریشده یاد میگیرد - به این معنی که هر ورودی یک خروجی صحیح متناظر دارد. مدل پیشبینیهایی انجام میدهد و آنها را با خروجیهای واقعی مقایسه میکند و خود را برای کاهش خطاها و بهبود دقت در طول زمان تنظیم میکند. هدف، پیشبینیهای دقیق روی دادههای جدید و دیده نشده است. به عنوان مثال، مدلی که روی تصاویر ارقام دستنویس آموزش دیده است، میتواند ارقام جدیدی را که قبلاً ندیده است، تشخیص دهد.

یادگیری نظارتشده نوعی یادگیری ماشینی است که در آن یک مدل از دادههای برچسبگذاریشده یاد میگیرد - به این معنی که هر ورودی یک خروجی صحیح متناظر دارد. مدل پیشبینیهایی انجام میدهد و آنها را با خروجیهای واقعی مقایسه میکند و خود را برای کاهش خطاها و بهبود دقت در طول زمان تنظیم میکند. هدف، پیشبینیهای دقیق روی دادههای جدید و دیده نشده است. به عنوان مثال، مدلی که روی تصاویر ارقام دستنویس آموزش دیده است، میتواند ارقام جدیدی را که قبلاً ندیده است، تشخیص دهد.
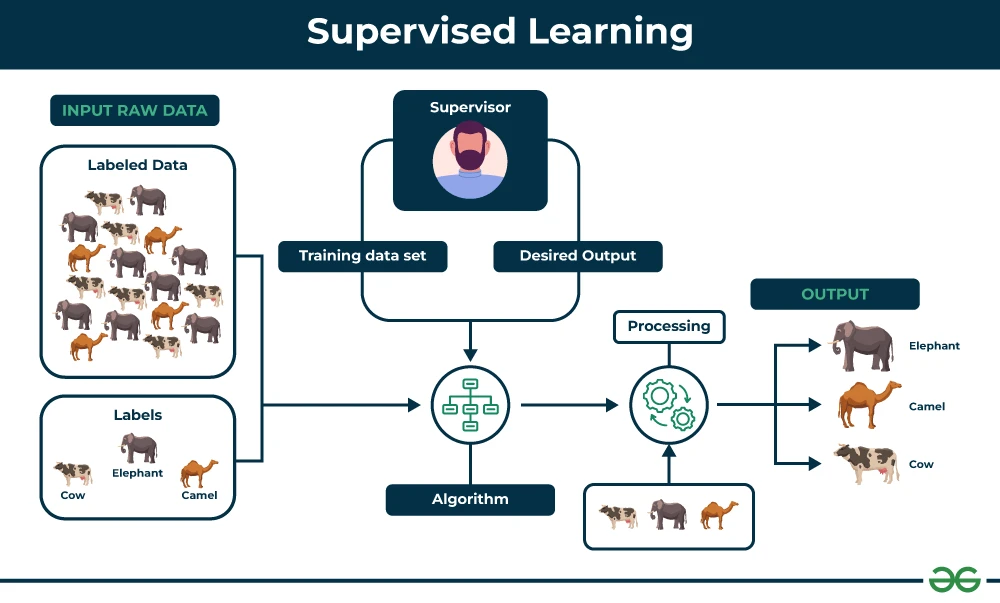
انواع یادگیری نظارتشده در یادگیری ماشین
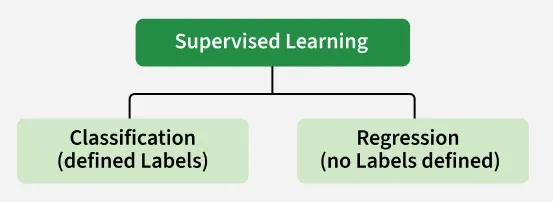
اکنون، یادگیری نظارتشده را میتوان برای دو نوع اصلی از مسائل به کار برد:
- دستهبندی: جایی که خروجی یک متغیر دستهبندیشده است (مثلاً ایمیلهای اسپم در مقابل ایمیلهای غیراسپم، بله در مقابل خیر).
- رگرسیون: جایی که خروجی یک متغیر پیوسته است (مثلاً پیشبینی قیمت خانه، قیمت سهام).
هنگام آموزش مدل، دادهها معمولاً به نسبت ۸۰:۲۰ تقسیم میشوند، یعنی ۸۰٪ به عنوان دادههای آموزشی و بقیه به عنوان دادههای آزمایشی. در دادههای آموزشی، ما ورودی و خروجی را برای ۸۰٪ از دادهها ارائه میدهیم. مدل فقط از دادههای آموزشی یاد میگیرد. ما از الگوریتمهای یادگیری نظارتشده مختلف (که در بخش بعدی به تفصیل در مورد آنها بحث خواهیم کرد) برای ساخت مدل خود استفاده میکنیم. ابتدا بیایید دادههای طبقهبندی و رگرسیون را از طریق جدول زیر درک کنیم:
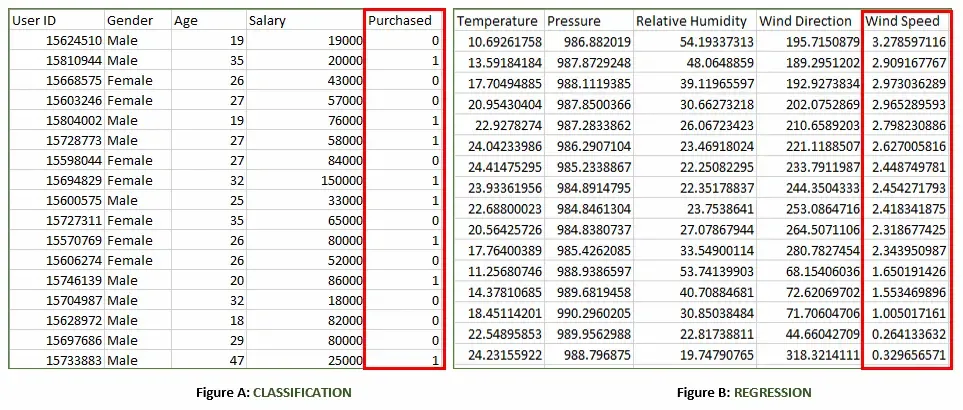
هر دو شکل بالا مجموعه دادههای برچسبگذاری شده به شرح زیر دارند:
شکل الف: این یک مجموعه داده از یک فروشگاه خرید است که در پیشبینی اینکه آیا مشتری محصول مورد نظر را بر اساس جنسیت، سن و حقوق خود خریداری خواهد کرد یا خیر، مفید است.
ورودی: جنسیت، سن، حقوق
خروجی: خریداری شده یعنی ۰ یا ۱؛ ۱ به این معنی است که مشتری آن را خریداری خواهد کرد و ۰ به این معنی است که مشتری آن را خریداری نخواهد کرد.
شکل ب: این یک مجموعه داده هواشناسی است که هدف آن پیشبینی سرعت باد بر اساس پارامترهای مختلف است.
ورودی: نقطه شبنم، دما، فشار، رطوبت نسبی، جهت باد
خروجی: سرعت باد
کارکرد یادگیری ماشین تحت نظارت
کارکرد یادگیری ماشین تحت نظارت از این مراحل کلیدی پیروی میکند:
۱. جمعآوری دادههای برچسبگذاری شده
یک مجموعه داده جمعآوری کنید که در آن هر ورودی یک خروجی صحیح شناخته شده (برچسب) داشته باشد.
مثال: تصاویر ارقام دستنویس با شماره واقعی آنها به عنوان برچسب.
۲. تقسیم مجموعه دادهها
دادهها را به دادههای آموزشی (حدود ۸۰٪) و دادههای آزمایشی (حدود ۲۰٪) تقسیم کنید.
مدل از دادههای آموزشی یاد میگیرد و روی دادههای آزمایشی ارزیابی میشود.
۳. مدل را آموزش دهید
دادههای آموزشی (ورودیها و برچسبهای آنها) را به یک الگوریتم یادگیری نظارتشده مناسب (مانند درختهای تصمیمگیری، SVM یا رگرسیون خطی) بدهید.
مدل سعی میکند الگوهایی را پیدا کند که ورودیها را برای تصحیح خروجیها نگاشت میکنند.
۴. اعتبارسنجی و آزمایش مدل
مدل را با استفاده از دادههای آزمایشی که قبلاً ندیده است، ارزیابی کنید.
مدل خروجیها را پیشبینی میکند و این پیشبینیها با برچسبهای واقعی مقایسه میشوند تا دقت یا خطا محاسبه شود.
۵. استقرار و پیشبینی روی دادههای جدید
هنگامی که مدل به خوبی عمل کرد، میتوان از آن برای پیشبینی خروجیها برای دادههای کاملاً جدید و دیده نشده استفاده کرد.
الگوریتمهای یادگیری ماشین نظارتشده
یادگیری نظارتشده را میتوان به چندین نوع مختلف تقسیم کرد که هر کدام ویژگیها و کاربردهای منحصر به فرد خود را دارند. در اینجا برخی از رایجترین انواع الگوریتمهای یادگیری نظارتشده آورده شده است:
- رگرسیون خطی: رگرسیون خطی نوعی الگوریتم رگرسیون یادگیری نظارتشده است که برای پیشبینی یک مقدار خروجی پیوسته استفاده میشود. این یکی از سادهترین و پرکاربردترین الگوریتمها در یادگیری نظارتشده است.
- رگرسیون لجستیک: رگرسیون لجستیک نوعی الگوریتم طبقهبندی یادگیری نظارتشده است که برای پیشبینی یک متغیر خروجی دودویی استفاده میشود.
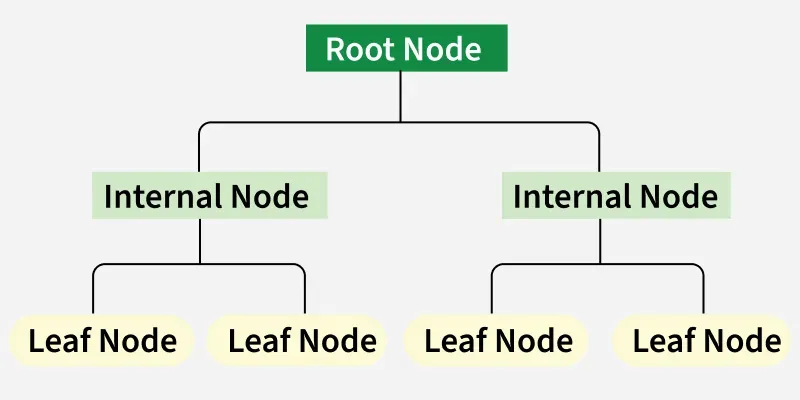
- درختهای تصمیمگیری: درخت تصمیمگیری ساختاری شبیه درخت است که برای مدلسازی تصمیمات و پیامدهای احتمالی آنها استفاده میشود. هر گره داخلی در درخت نشان دهنده یک تصمیم است، در حالی که هر گره برگ نشان دهنده یک نتیجه احتمالی است.
- جنگلهای تصادفی: جنگلهای تصادفی نیز از چندین درخت تصمیمگیری تشکیل شدهاند که برای پیشبینی با هم کار میکنند. هر درخت در جنگل بر روی زیرمجموعه متفاوتی از ویژگیها و دادههای ورودی آموزش داده میشود. پیشبینی نهایی با تجمیع پیشبینیهای همه درختان در جنگل انجام میشود.
- ماشین بردار پشتیبان (SVM): الگوریتم SVM یک ابرصفحه ایجاد میکند تا فضای n بعدی را به کلاسها تفکیک کند و دسته صحیح نقاط داده جدید را شناسایی کند. موارد حدی که به ایجاد ابرصفحه کمک میکنند، بردارهای پشتیبان نامیده میشوند، از این رو نام آن ماشین بردار پشتیبان است.
- K-نزدیکترین همسایهها: KNN با یافتن k نمونه آموزشی نزدیک به یک ورودی داده شده کار میکند و سپس کلاس یا مقدار را بر اساس کلاس اکثریت یا مقدار میانگین این همسایهها پیشبینی میکند. عملکرد KNN میتواند تحت تأثیر انتخاب k و معیار فاصله مورد استفاده برای اندازهگیری نزدیکی قرار گیرد.
- تقویت گرادیان: تقویت گرادیان، یادگیرندههای ضعیف، مانند درختهای تصمیمگیری، را برای ایجاد یک مدل قوی ترکیب میکند. این الگوریتم به صورت تکراری مدلهای جدیدی میسازد که خطاهای مدلهای قبلی را اصلاح میکنند.
- الگوریتم بیز ساده: الگوریتم بیز ساده یک الگوریتم یادگیری ماشین تحت نظارت است که مبتنی بر اعمال قضیه بیز با فرض "ساده" است که ویژگیها با توجه به برچسب کلاس، مستقل از یکدیگر هستند.
نمونههای عملی یادگیری نظارتشده
چند نمونه عملی از یادگیری ماشین نظارتشده در صنایع مختلف:
تشخیص تقلب در بانکداری: از الگوریتمهای یادگیری نظارتشده بر روی دادههای تراکنشهای تاریخی استفاده میکند و مدلهایی را با مجموعه دادههای برچسبگذاریشده از تراکنشهای قانونی و جعلی آموزش میدهد تا الگوهای کلاهبرداری را به طور دقیق پیشبینی کند.
پیشبینی بیماری پارکینسون: بیماری پارکینسون یک اختلال پیشرونده است که سیستم عصبی و قسمتهایی از بدن که توسط اعصاب کنترل میشوند را تحت تأثیر قرار میدهد.
پیشبینی ریزش مشتری: از تکنیکهای یادگیری نظارتشده برای تجزیه و تحلیل دادههای تاریخی مشتری استفاده میکند و ویژگیهای مرتبط با نرخ ریزش را برای پیشبینی مؤثر حفظ مشتری شناسایی میکند.
طبقهبندی سلولهای سرطانی: یادگیری نظارتشده را برای سلولهای سرطانی بر اساس ویژگیهای آنها پیادهسازی میکند و آنها را از نظر «بدخیم» یا «خوشخیم» بودن شناسایی میکند.
پیشبینی قیمت سهام: یادگیری نظارتشده را برای پیشبینی سیگنالی اعمال میکند که نشان میدهد خرید یک سهام خاص مفید خواهد بود یا خیر.
مزایا
در اینجا برخی از مزایای یادگیری نظارتشده ذکر شده است:
سادگی و وضوح: درک و پیادهسازی آن آسان است زیرا از نمونههای برچسبگذاریشده یاد میگیرد. دقت بالا: وقتی دادههای برچسبگذاریشده کافی در دسترس باشند، مدلها به عملکرد پیشبینیکننده قوی دست مییابند.
چندمنظوره بودن: برای طبقهبندی مانند تشخیص هرزنامه، پیشبینی بیماری و رگرسیون مانند پیشبینی قیمت کار میکند.
تعمیمپذیری: با دادههای متنوع کافی و آموزش مناسب، مدلها میتوانند به خوبی به ورودیهای دیده نشده تعمیم دهند.
کاربرد گسترده: در تشخیص گفتار، تشخیص پزشکی، تحلیل احساسات، تشخیص کلاهبرداری و موارد دیگر استفاده میشود.
معایب
نیاز به دادههای برچسبگذاریشده: آمادهسازی مقادیر زیادی از مجموعه دادههای برچسبگذاریشده پرهزینه و زمانبر است.
سوگیری از دادهها: اگر دادههای آموزشی سوگیریشده یا نامتعادل باشند، مدل ممکن است این سوگیریها را یاد بگیرد و تقویت کند.
خطر بیشبرازش: مدل ممکن است به جای یادگیری الگوهای کلی، دادههای آموزشی را به خاطر بسپارد، به خصوص با مجموعه دادههای کوچک.
سازگاری محدود: عملکرد هنگام اعمال بر روی توزیعهای داده بسیار متفاوت از دادههای آموزشی به طور قابل توجهی کاهش مییابد.
برای برخی از مشکلات مقیاسپذیر نیست: در کارهایی با میلیونها برچسب ممکن مانند زبان طبیعی، برچسبگذاری نظارتشده غیرعملی میشود.








![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/4cae76fd106344cfae5ff4ddb16139ca.png)
![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/785203d10bad4f8fb87e8c29efefb5df.jpg)
![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/f1ffeacc8ad14ae5b6d7deb528036232.jpg)
![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/d42b325ccf7848d5bb089d6479f9991b.png)





0 دیدگاه