

فناوری رایانه ای - هوش مصنوعی
یادگیری ماشین بدون نظارت (Unsupervised Machine Learning) چیست؟
یادگیری بدون نظارت نوعی یادگیری ماشینی است که دادهها را بدون پاسخهای برچسبگذاری شده یا دستههای از پیش تعریف شده تجزیه و تحلیل و مدلسازی میکند. برخلاف یادگیری تحت نظارت، که در آن الگوریتم از جفتهای ورودی-خروجی یاد میگیرد، الگوریتمهای یادگیری بدون نظارت صرفاً با دادههای ورودی کار میکنند و هدفشان کشف الگوها، ساختارها یا روابط پنهان در مجموعه دادهها به طور مستقل و بدون هیچ گونه دخالت انسانی یا دانش قبلی از معنای دادهها است.

یادگیری بدون نظارت نوعی یادگیری ماشینی است که دادهها را بدون پاسخهای برچسبگذاری شده یا دستههای از پیش تعریف شده تجزیه و تحلیل و مدلسازی میکند. برخلاف یادگیری تحت نظارت، که در آن الگوریتم از جفتهای ورودی-خروجی یاد میگیرد، الگوریتمهای یادگیری بدون نظارت صرفاً با دادههای ورودی کار میکنند و هدفشان کشف الگوها، ساختارها یا روابط پنهان در مجموعه دادهها به طور مستقل و بدون هیچ گونه دخالت انسانی یا دانش قبلی از معنای دادهها است.
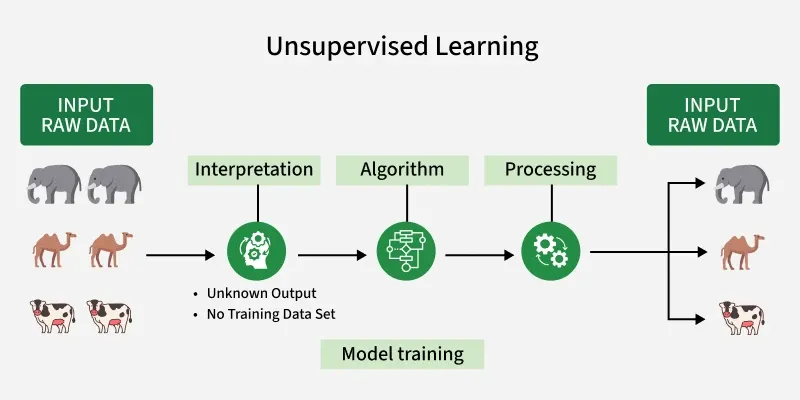
تصویر مجموعهای از حیوانات مانند فیل، شتر و گاو را نشان میدهد که نشاندهنده دادههای خامی است که الگوریتم یادگیری بدون نظارت پردازش خواهد کرد.
مرحله «تفسیر» نشان میدهد که الگوریتم برچسب یا دستهبندی از پیش تعریفشدهای برای دادهها ندارد. باید بفهمد که چگونه دادهها را بر اساس الگوهای ذاتی گروهبندی یا سازماندهی کند.
یک الگوریتم نشاندهنده فرآیند یادگیری بدون نظارت است که میتواند خوشهبندی، کاهش ابعاد یا تشخیص ناهنجاری برای شناسایی الگوها در دادهها باشد.
مرحله پردازش، الگوریتمی را نشان میدهد که روی دادهها کار میکند.
خروجی، نتایج فرآیند یادگیری بدون نظارت را نشان میدهد. در این حالت، الگوریتم ممکن است حیوانات را بر اساس گونههایشان (فیل، شتر، گاو) در خوشههایی گروهبندی کرده باشد.
کارکرد یادگیری بدون نظارت
کارکرد یادگیری ماشین بدون نظارت را میتوان در این مراحل توضیح داد:
1. جمعآوری دادههای بدون برچسب
جمعآوری یک مجموعه داده بدون برچسب یا دستهبندی از پیش تعریفشده.
مثال: تصاویر حیوانات مختلف بدون هیچ برچسبی.
۲. انتخاب یک الگوریتم
یک الگوریتم بدون نظارت مناسب مانند خوشهبندی مانند K-Means، یادگیری قانون وابستگی مانند Apriori یا کاهش ابعاد مانند PCA را بر اساس هدف انتخاب کنید.
۳. آموزش مدل با دادههای خام
کل مجموعه دادههای بدون برچسب را به الگوریتم بدهید.
این الگوریتم به دنبال شباهتها، روابط یا ساختارهای پنهان در دادهها میگردد.
۴. گروهبندی یا تبدیل دادهها
این الگوریتم دادهها را بدون ورودی انسان در گروهها (خوشهها)، قوانین یا اشکال با ابعاد پایینتر سازماندهی میکند.
مثال: ممکن است حیوانات مشابه را با هم گروهبندی کند یا الگوهای کلیدی را از مجموعه دادههای بزرگ استخراج کند.
۵. تفسیر و استفاده از نتایج
گروهها، قوانین یا ویژگیهای کشف شده را برای کسب بینش یا استفاده از آنها برای کارهای بیشتر مانند تجسم، تشخیص ناهنجاری یا به عنوان ورودی برای سایر مدلها تجزیه و تحلیل کنید.
الگوریتمهای یادگیری بدون نظارت
عمدتاً ۳ نوع الگوریتم بدون نظارت وجود دارد که استفاده میشوند:
۱. الگوریتمهای خوشهبندی
خوشهبندی یک تکنیک یادگیری ماشین بدون نظارت است که دادههای بدون برچسب را بر اساس شباهت در خوشهها گروهبندی میکند. هدف آن کشف الگوها یا روابط درون دادهها بدون هیچ دانش قبلی از دستهها یا برچسبها است.
- نقاط دادهای را که ویژگیها یا مشخصات مشابهی دارند، گروهبندی میکند.
- به یافتن گروهبندیهای طبیعی در دادههای خام و طبقهبندی نشده کمک میکند.
- معمولاً برای تقسیمبندی مشتری، تشخیص ناهنجاری و سازماندهی دادهها استفاده میشود.
- صرفاً از دادههای ورودی بدون هیچ برچسب خروجی کار میکند.
- درک ساختار دادهها را برای تجزیه و تحلیل بیشتر یا تصمیمگیری امکانپذیر میسازد.
برخی از الگوریتمهای خوشهبندی رایج:
- خوشهبندی K-means: دادهها را بر اساس میزان نزدیکی نقاط به یکدیگر در K خوشه گروهبندی میکند.
- خوشهبندی سلسله مراتبی: با ساختن یک درخت گام به گام، چه با ادغام و چه با تقسیم گروهها، خوشهها را ایجاد میکند.
- خوشهبندی مبتنی بر چگالی (DBSCAN): خوشهها را در مناطق متراکم پیدا میکند و نقاط پراکنده را به عنوان نویز در نظر میگیرد.
- خوشهبندی میانگین-تغییر: با حرکت نقاط به سمت شلوغترین مناطق، خوشهها را کشف میکند.
- خوشهبندی طیفی: با تجزیه و تحلیل ارتباطات بین نقاط با استفاده از نمودارها، دادهها را گروهبندی میکند.
2. یادگیری قانون وابستگی
یادگیری قانون وابستگی یک تکنیک یادگیری بدون نظارت مبتنی بر قانون است که برای کشف روابط جالب بین متغیرها در مجموعه دادههای بزرگ استفاده میشود. این روش الگوها را به شکل قوانین "اگر-آنگاه" شناسایی میکند و نشان میدهد که چگونه حضور برخی از اقلام در دادهها، نشاندهنده حضور برخی دیگر است.
ترکیبات مکرر اقلام و قوانین مرتبط با آنها را پیدا میکند.
معمولاً در تحلیل سبد بازار برای درک روابط خرید محصول استفاده میشود.
به خردهفروشان در طراحی تبلیغات و استراتژیهای فروش متقابل کمک میکند.
برخی از الگوریتمهای رایج یادگیری قانون وابستگی:
- الگوریتم Apriori: با بررسی گام به گام ترکیبات مکرر اقلام، الگوها را پیدا میکند.
- الگوریتم FP-Growth: جایگزینی کارآمد برای Apriori. این الگوریتم به سرعت الگوهای پرتکرار را بدون ایجاد مجموعههای کاندید شناسایی میکند.
- الگوریتم Eclat: از تقاطع مجموعههای آیتم برای یافتن کارآمد الگوهای پرتکرار استفاده میکند.
- الگوریتمهای کارآمد مبتنی بر درخت: با سازماندهی دادهها در ساختارهای درختی، برای مدیریت مجموعههای داده بزرگ مقیاسبندی میشوند.
۳. کاهش ابعاد
کاهش ابعاد فرآیند کاهش تعداد ویژگیها یا متغیرها در یک مجموعه داده است، در حالی که تا حد امکان اطلاعات اصلی را حفظ میکند. این تکنیک به سادهسازی دادههای پیچیده کمک میکند و تجزیه و تحلیل و تجسم آنها را آسانتر میکند. همچنین با کاهش نویز و هزینه محاسباتی، کارایی و عملکرد الگوریتمهای یادگیری ماشین را بهبود میبخشد.
فضای ویژگیهای مجموعه داده را از ابعاد زیاد به ابعاد کمتر و معنادارتر کاهش میدهد.
به تمرکز بر مهمترین ویژگیها یا الگوهای موجود در دادهها کمک میکند.
معمولاً برای بهبود سرعت مدل و کاهش بیشبرازش استفاده میشود.
در اینجا برخی از الگوریتمهای محبوب کاهش ابعاد آورده شده است:
- تحلیل مؤلفه اصلی (PCA): با تبدیل دادهها به مؤلفههای اصلی غیرهمبسته، ابعاد را کاهش میدهد.
- تحلیل تفکیک خطی (LDA): ابعاد را کاهش میدهد و در عین حال تفکیکپذیری کلاسها را برای وظایف طبقهبندی به حداکثر میرساند.
- تجزیه ماتریس غیرمنفی (NMF): دادهها را به n تجزیه میکند.
- جاسازی خطی محلی (LLE): ابعاد را کاهش میدهد و در عین حال روابط بین نقاط نزدیک را حفظ میکند.
- ایزومپ: ساختار دادههای جهانی را با حفظ فواصل در امتداد یک منیفولد ثبت میکند.
کاربردهای یادگیری بدون نظارت
یادگیری بدون نظارت کاربردهای متنوعی در صنایع و حوزهها دارد. کاربردهای کلیدی عبارتند از:
- بخشبندی مشتری: الگوریتمها مشتریان را بر اساس رفتار خرید یا جمعیتشناسی خوشهبندی میکنند و استراتژیهای بازاریابی هدفمند را ممکن میسازند.
- تشخیص ناهنجاری: الگوهای غیرمعمول در دادهها را شناسایی میکند و به تشخیص تقلب، امنیت سایبری و جلوگیری از خرابی تجهیزات کمک میکند.
- سیستمهای توصیهگر: با تجزیه و تحلیل رفتار و ترجیحات کاربر، محصولات، فیلمها یا موسیقی را پیشنهاد میدهد.
- خوشهبندی تصویر و متن: تصاویر یا اسناد مشابه را برای کارهایی مانند سازماندهی، طبقهبندی یا توصیه محتوا گروهبندی میکند.
- تحلیل شبکه اجتماعی: جوامع یا روندهای تعاملات کاربر را در پلتفرمهای رسانههای اجتماعی تشخیص میدهد.
مزایا
- نیازی به دادههای برچسبگذاری شده نیست: با دادههای خام و بدون برچسب کار میکند و از این رو در زمان و تلاش برای حاشیهنویسی دادهها صرفهجویی میکند.
- الگوهای پنهان را کشف میکند: گروهبندیها و ساختارهای طبیعی را که ممکن است توسط انسانها از دست رفته باشند، پیدا میکند.
- مجموعه دادههای پیچیده و بزرگ را مدیریت میکند: برای دادههای با ابعاد بالا یا حجم زیاد موثر است.
- برای تشخیص ناهنجاری مفید است: میتواند دادههای پرت و نقاط داده غیرمعمول را بدون مثالهای قبلی شناسایی کند.
چالشها
چالشهای کلیدی یادگیری بدون نظارت عبارتند از:
- دادههای نویزی: دادههای پرت و نویز میتوانند الگوها را تحریف کرده و اثربخشی الگوریتمها را کاهش دهند.
- وابستگی به فرض: الگوریتمها اغلب به فرضیاتی (مثلاً شکل خوشهها) متکی هستند که ممکن است با ساختار داده واقعی مطابقت نداشته باشند.
- ریسک بیشبرازش: بیشبرازش میتواند زمانی رخ دهد که مدلها به جای الگوهای معنادار در دادهها، نویز را ثبت کنند.
- راهنمایی محدود: عدم وجود برچسبها، توانایی هدایت الگوریتم به سمت نتایج خاص را محدود میکند.
- تفسیرپذیری خوشه: نتایجی مانند خوشهها ممکن است فاقد معنای واضح یا همترازی با دستههای دنیای واقعی باشند.
- حساسیت به پارامترها: بسیاری از الگوریتمها نیاز به تنظیم دقیق پارامترهایی مانند تعداد خوشهها در k-means دارند.
- فقدان حقیقت زمینی: یادگیری بدون نظارت فاقد دادههای برچسبگذاری شده است که ارزیابی دقت نتایج را دشوار میکند.








![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/4cae76fd106344cfae5ff4ddb16139ca.png)
![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/785203d10bad4f8fb87e8c29efefb5df.jpg)
![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/d42b325ccf7848d5bb089d6479f9991b.png)
![articleItemsMostView[i].ThumnailImageName](/images/Articles/Thumbnails/f1ffeacc8ad14ae5b6d7deb528036232.jpg)




0 دیدگاه